I have a machine learning model that can analyze what number is depicted in a picture.
What number is this?
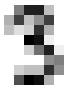
3
What number is this?
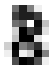
8
What about this?

7
Extrapolation in Supervised Machine Learning
Supervised machine learning methods are a subset of machine learning which, given a datapoint composed of known attributes, predict an unknown target attribute. They achieve this task by training their predictive model on a set of datapoints with pre-labeled target values, finding patterns of relation between the known traits and the target trait.The model’s predictions are ‘supervised’ by the training algorithm in that they are judged against the true target labels in the training dataset. Supervised methods are the most commonly used machine learning tactic today, as they are especially effective at automating the prediction of complex relations between known inputs and outputs, a skill which allows programmers to automate human evaluations of data. These models, however, lack a subtle but crucial trait humans use without realizing in prediction. In trusting them to evaluate data without oversight, programmers open ourselves up to vulnerabilities which would never occur in the human evaluations these systems mimic.
When a human is given a data evaluation task, they effortlessly recognize when the data they are given is abnormal. In an effective task structure, if the abnormality seems relevant to the evaluation, the data is marked as unable-to-eval and/or escalated to someone with more knowledge. As with most computer programs, supervised learning methods are content to take in clearly anomalous data and indiscriminately process it.
In some respects the capacity to extrapolate is desired! In traditionally written code, more general programs are usually considered more refined for two reasons: (1) they reduce the amount of new code which may need to be written in the future, and (2) their design grasps a deeper abstracted general problem underlying the more immediate problem at hand. The second is clearly inapplicable to supervised learning methods, as their capacity to function on new data is not an abstraction away from the immediate problem, but rather an application of the current heuristics to a new domain. The first is true only on the condition that the model extrapolates outside its training set accurately… which may be true, but may as well not be. A programmer has no way to know if their model extrapolates well into a new domain without hand-labeling data from that domain and evaluating the model against it. Without a way to isolate and manually label the anomalous input from the sea of data fed into the model for judgement, we risk extrapolating into a domain our model is completely unequipped to judge. Worst of all, we wouldn’t even know that our model performed an erroneous judgement, because to it the inputs’ differences from the training set are completely ignored.
Luckily there is a way for our model to notice strange input: Anomaly Detection. Anomaly detection algorithms are a class of machine learning focused on identifying anomalous data. There are many ways to perform this task, with some being more suited to particular situations than others. Regardless of which anomaly detection algorithm is used, incorporating anomaly detection into a supervised learning model is easy! Just train an anomaly detection algorithm on the same data your model is trained on, and if the detector goes off on a production datapoint return an error instead of an evaluation. This allows whatever system the model is interacting with to handle the anomalous data whatever way it wants, storing it for human inspection, skipping further processing on the data in the same pipeline, etc.
A Solution In Practice

Let’s say I wrote a machine learning program to recognize images of handwritten numbers. It’s intended to be used in reading ID codes on scanned library stack cards. It’s 98% accurate on data it’s never seen before, which is good! Good enough to deploy at least.

A few weeks after I deployed it one of the librarian assistants came to me saying that the model started outputting numbers totally irrelevant from the numbers on the cards. This could have been going on for a while, since they only noticed after searching for some of the IDs they knew were in the prior day’s stack and not finding them in the system.
Why? After a few hours of scrutinizing and testing my model, no bugs showed… until I checked the input data. Evidently the scanner’s backlight broke, and the camera was boosting the contrast on nearly-black document to try and get a good picture, resulting in pure noise.

My model took in the data and happily spit out judgements as to what number it most associated with the noise. While we sought a replacement bulb for the scanner, I wrote some code to ensure that the model wouldn’t overconfidently judge data it didn’t fully understand again.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
The solution was relatively simple! I ran an out-of-the-box implementation of the Local Outlier Factor algorithm, which is a density estimator, on the data input. I wrote a composite function which ran the density estimator on the data, and, when an outlier was detected, returned -1 rather than an evaluation from 0 to 9. This captures testing data that are clearly different from the training set (such as random data, significantly darker or lighter than normal data, and data that’s been offset from the center of the frame) while letting through data that generally seems similar to the input data. The Local Outlier Factor algorithm may not be the best algorithm for every case, but it was a good one for this particular task. Any method of producing a predictive model that judges whether a new datapoint is inside or outside the training domain will function to produce the desired capability in a composite model.




It is important to remember that the Local Outlier Factor model’s goal is not directly to guess which data the classifier will misclassify, but rather to guess which data are different from the input set. It may be true that an entire class of data (like washed out numbers) are classified correctly by the model, but in that case it is still valuable for the programmer to be alerted when these new data show up so that they can be hand-labeled and added to the model’s training set on a successive version. Re-training the supervised learning model explicitly on data which was rejected as an outlier results in the model’s domain growing with a cautious purposefulness that lends it a much greater reliability in practice. It enables the programmer to judiciously label data which will increase the model’s domain, and not waste time hand-labeling data which does not improve the model because it is situated in a domain the model already understands.
A reasonable question could be: why did I have to add the unsupervised method into my supervised learning paradigm? Couldn’t I have added an extra label, -1, to my supervised model’s category list, and provided labeled noise as part of the training data? At first glance it seems to be a simpler solution than adding an entire other learning model. There are a few reasons why this would harm the supervised model’s overall accuracy. For one, it would require us to know what the outliers will look like prior to our training the model, when the point of this task is that we want to identify data we didn’t expect. We would have to know what we didn’t expect to see in the input prior to seeing it. For another, we would have to balance the amount of outlier input we provide the supervised model, so as to not bias the model’s expectation that any given datapoint is an outlier. My categorical model (a one layer convolutional neural network), were it to be trained on too many outliers, would expect a new datapoint to be an outlier, and would require strong correlations between the new datapoint and another category to outweigh that prior bias. By using an unsupervised model for outlier detection, we minimize the effect that this addition has on the already developed predictive model that it assists.
Don’t Ignore This Advice!
This may seem like a suggestion, but domain modeling is an inexpensive addition to most machine learning programs that increases their accuracy and longevity. It’s also a good use of resources for improving a model which appears to be promising, since it can be used to collect optimal additional training data. Extrapolation can lead to systemic error that often goes unnoticed for long stretches of time, which, depending on how important your model is, can cause serious harm. The addition of even a simple out-of-the-box domain modeler mitigates the most egregious cases of extrapolation, and putting in the effort to implement a more nuanced domain modeler will catch more fine-grained cases of extrapolation.