It’s common practice in the tech sector today to excite investors, job applicants, and news organizations by using the term “machine learning.” As the term grew in popularity in the latter half of the 2010s, its definition slid from academic to cultural, from rigid to soft. Where previously only machine learning engineers used the term, now most individuals who engage with current news need to at least understand vaguely what the term means. The result is a blurring of machine learning’s commonly understood meaning. This transition isn’t necessarily bad—it’s a natural result of an academic term becoming a common conversation topic—but a soft definition does create more space for miscommunication, especially when the new soft definition is reintegrated into academia through a new generation of students and researchers. Maintaining a clear definition of machine learning is important for ensuring everyone understands what everyone else means when they use the phrase.
Linguistic Approaches to Definitions
In linguistics, there are two perspectives on how to investigate language features. The older of the two is prescriptivism, in which linguists look at a language’s agreed-upon definitions and conventions, and use those to judge peoples’ language usage as either right or wrong. The more contemporary of the two is called descriptivism. Descriptivist linguists seek to describe how language is used by people who speak it, not how speakers claim it should be used. Often how we assert we should speak and how we actually speak don’t align perfectly.
An available case of this disagreement is how the two groups treat infinitive-splitting in English. Prescriptivist English grammarians dictate that nobody should ever split an infinitive (”I want to accurately meet your specification”), opting to bring adverbs outside of the infinitive (”I want to meet your specification accurately”). Descriptive English syntacticians observe that English speakers naturally split infinitives in everyday speech despite their being taught not to do so. For this reason, descriptive syntacticians accept infinitive-splitting as part of natural English grammar. Descriptive linguistics dominates the higher-academic field in part because it’s able to capture the way languages evolve over time. Prescriptive linguists slowly drift apart from how language is presently used until they are describing a language which no longer exists, or until a new set of language rules are established and they begin the slow desynchronization process again.
Descriptive and prescriptive linguists also have different approaches to constructing definitions. To the prescriptive linguist, definitions exist in language a priori, and do not change over time. When a new term is created, its definition is set in stone. To the descriptive linguist, a definition is entirely based on how the term is used. This is how Merriam-Webster came to define “literally” as “in effect : virtually” in 2011. Since the word was commonly used to as emphasis at the time, its descriptive definition changed to account for that usage.
Descriptive definitions are better at capturing a term’s common meaning, and at introducing people unfamiliar with the term to how they should expect to see it used. Still, there is benefit to the prescriptive perspective. Prescriptive definitions can to be simpler than descriptive definitions, because they don’t have to account for the wide smear of uses a word acquires as it slowly evolves. Prescriptive definitions are used in academic and professional settings because a fixed definition clarifies discussion of complex subjects.
A descriptive definition for machine learning, one which captures all of the term’s myriad uses, wouldn’t clarify the now fuzzy definition at all. Rather, such a definition would encode the vagueness of the current term’s usage. What we’re looking for in a new definition of machine learning, then, is a compromise between prescriptive and descriptive definitions, selecting for a certain category of usage to describe. To figure out what uses to consider, we can look back at why the current term is so mired: non-technical references to “machine learning” lead people to misunderstanding its real-world meaning. Analyzing the commonalities in how machine learning engineers use the term “machine learning” can give us a specific descriptive definition of machine learning separate from its popular usage.
Comparing Types of Machine Learning Algorithms
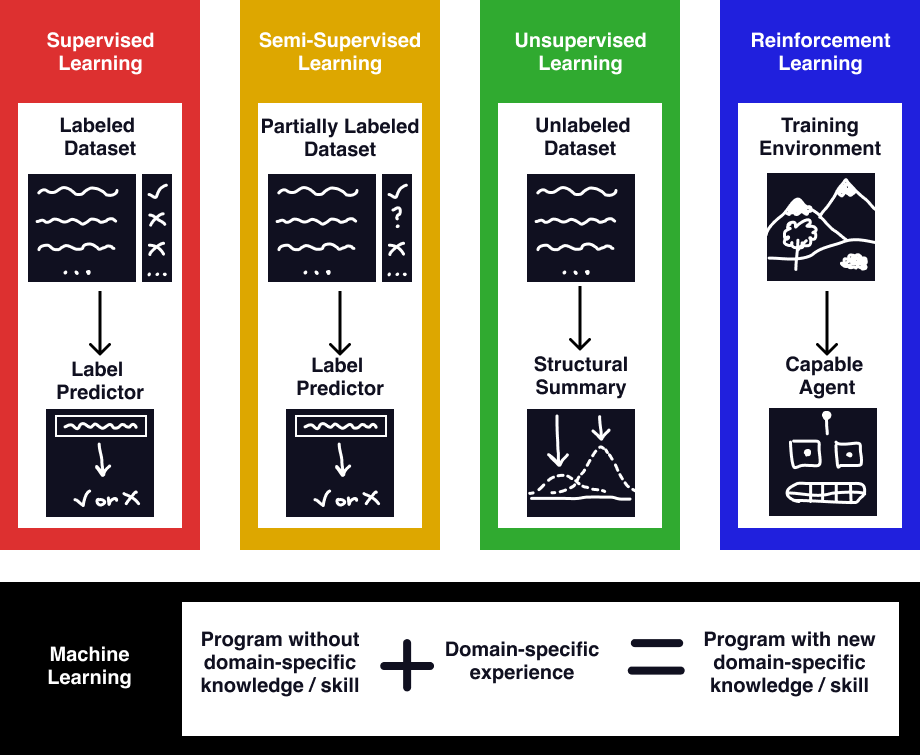
There are four ways “machine learning” is used by machine learning engineers. The four machine learning paradigms are supervised, unsupervised, semi-supervised, and reinforcement learning. Since these exhaustively cover all algorithms understood to be machine learning today, a definition which characterizes all four will necessarily be one which covers all current machine learning algorithms. The shared traits between these paradigms specify a definition which describes all of them.
Supervised learning algorithms are provided a dataset of individual data points, each with a labeled target attribute. They use that input to learn associations between the target attribute and the rest of the data points’ attributes. Once done learning from the dataset, those associations are deployed to predict labels for novel unlabeled data. Examples of supervised learning algorithms are polynomial regression, naive-bayes classifiers, and support-vector machines. Supervised learning is by far the most common class of machine learning algorithms, since it can be used as an automation tool for human tasks. Rather than having a human identify pictures of birds, a supervised learning method can be trained on human-labeled photos of birds to identify them accurately, obviating the original labeler’s job. It’s incredibly easy to test supervised learning algorithms by checking their predictions against new labeled data, verifying their efficacy.
Unsupervised learning algorithms learn about a dataset without predicting a specific target attribute of the data. They don’t have a target to learn about, so the variety of unsupervised learning techniques are broader than supervised learning. Unsupervised learning can model what values are expected in the dataset (as in anomaly detection), it can find distinct clusters in the data (gaussian-mixture-models, and latent Dirichlet allocation), and it can find correlations between different attributes of their datapoints (ex. primary component analysis). Similar to classical statistics, unsupervised learning is useful in gaining insight about a dataset.
Semi-supervised learning algorithms are essentially mixes of supervised and unsupervised learning algorithms, in which some of the data is labeled and others are not. The access to unlabeled data can help the program train more accurately on the smaller labeled dataset it is afforded, in using the relations learned in the large dataset to assist predictions in the small dataset. When acquiring labeled data is difficult, semi-supervised learning techniques can be the difference between a working model and a broken one.
Reinforcement learning algorithms are the most unique of the four, and are structured around autonomous agents maximizing their reward within an environment. These do not train on datasets, but rather interact with an environment and are given rewards for completing desired goals. One example of reinforcement learning is a mechanical arm and camera attempting to grab an object. The optimal way to grab an object is difficult to express to the computer, but it can learn on its own via trial and error, with reward being given upon a successful grab. Reinforcement algorithms tend to be uncommon, as they require spontaneous feedback to novel solutions from the program, which may need to be evaluated by hand on a case-to-case basis, or in an environment which needs to be manually reset. Still, in some scenarios, they are by far the most effective method, especially if an automated test-environment, or “teacher” can be encoded. In fact, this is what occurs in generative adversarial networks (GANs), which use a powerful “discriminator” supervised algorithm to train a “generator” reinforcement algorithm.
Now that we know what each of these algorithms are, we can start looking at commonalities between them. Finding the shared traits of all four paradigms at once is difficult to do, but a much easier task is iteratively combining similar paradigms until we reach the center of the Venn diagram. Doing so lets us compare just two groups of algorithms at a time, rather than all the algorithms at once. I’ve put stars in each of the sections of the diagram we’ve discussed so far.
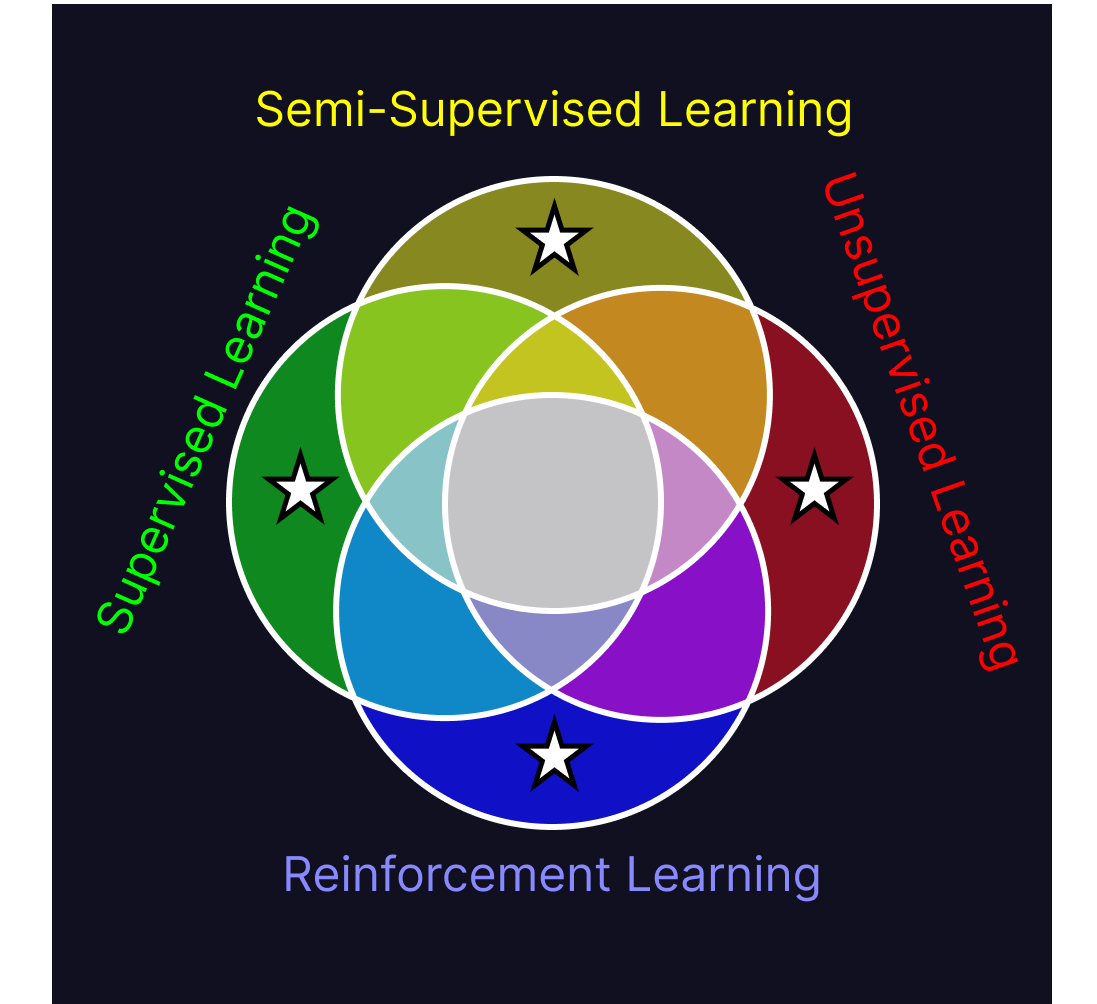
Looking at the commonalities between supervised and semi-supervised learning, both attempt to predict a target value based on the values of their input data. Supervised learning does so based only on the relations it’s learned between individual data and their associated target value, whereas semi-supervised learning also explicitly learns about internal structure in the dataset as a whole and how that can be used to help predict the target value.
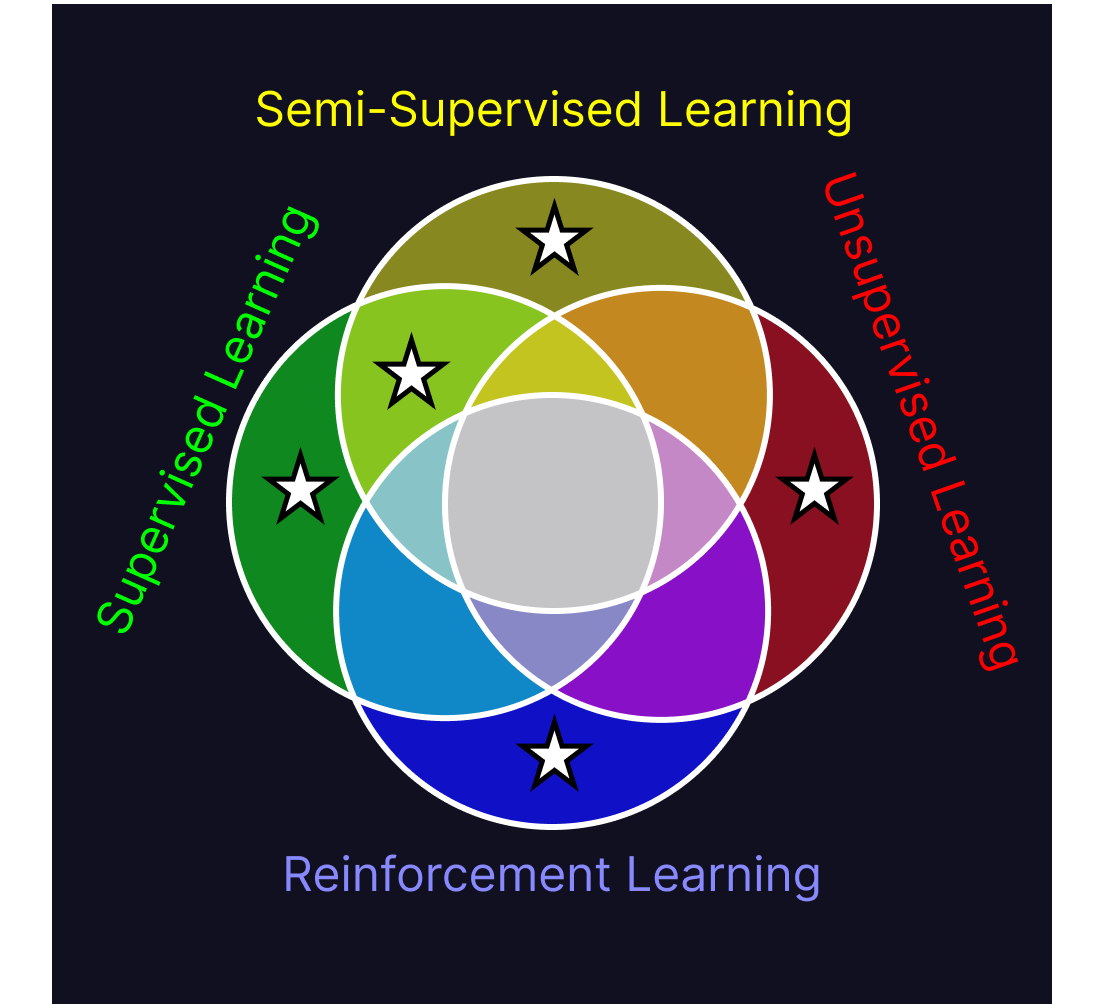
Semi-supervised learning and unsupervised learning both learn about the structure of their datasets. Semi-supervised learning does so in order to find insight into a target value, whereas unsupervised learning does so for the value that structural knowledge of the dataset provides on its own. While semi-supervised learning is deployed for the purpose of predicting a target attribute, unsupervised learning creates new attributes of the data (ex. what cluster is this datapoint), and can be deployed to assign new data points those novel attributes.
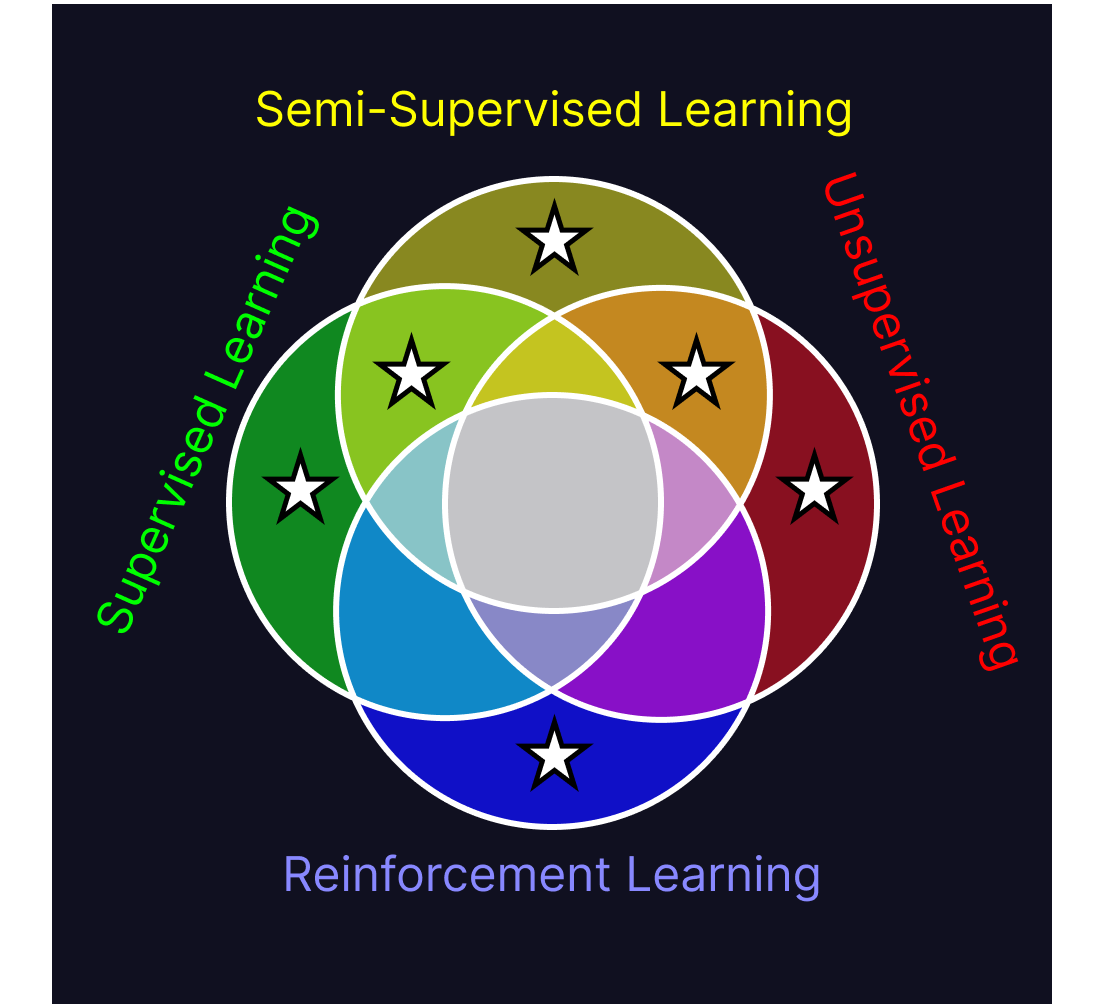
Supervised learning, semi-supervised learning and unsupervised learning all train variables using a pre-defined structure and learning method on existing datasets to produce models. In all of these techniques, those models then evaluate novel data similar to their training data. All of them have this structure: Set up model structure, train model on data, deploy model on novel data.
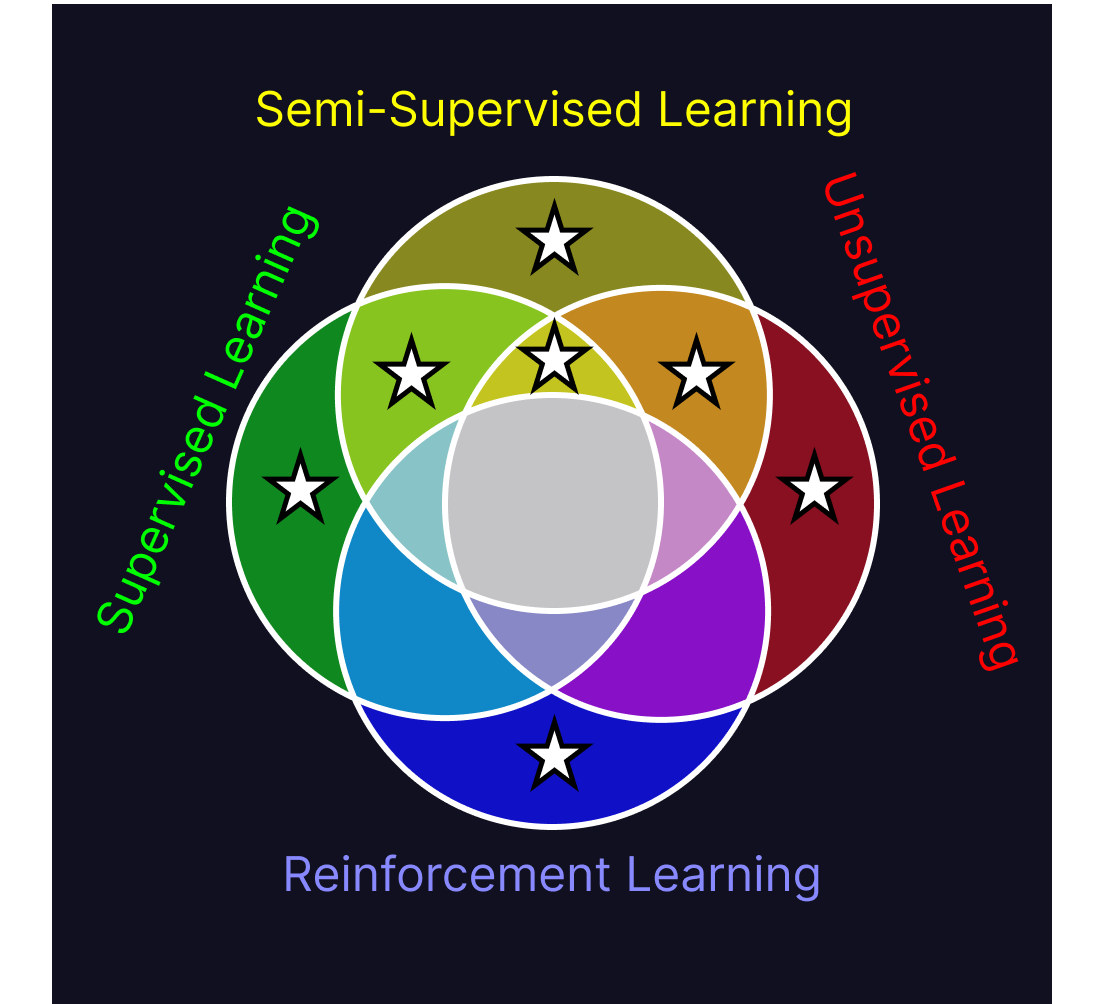
The difference between the gold segment, (the intersection of supervised learning, semi-supervised learning, and unsupervised learning), and reinforcement learning, is in their training method. The triplet here all have the commonality of learning information off of a dataset, whereas reinforcement learning trains within an interactive environment.
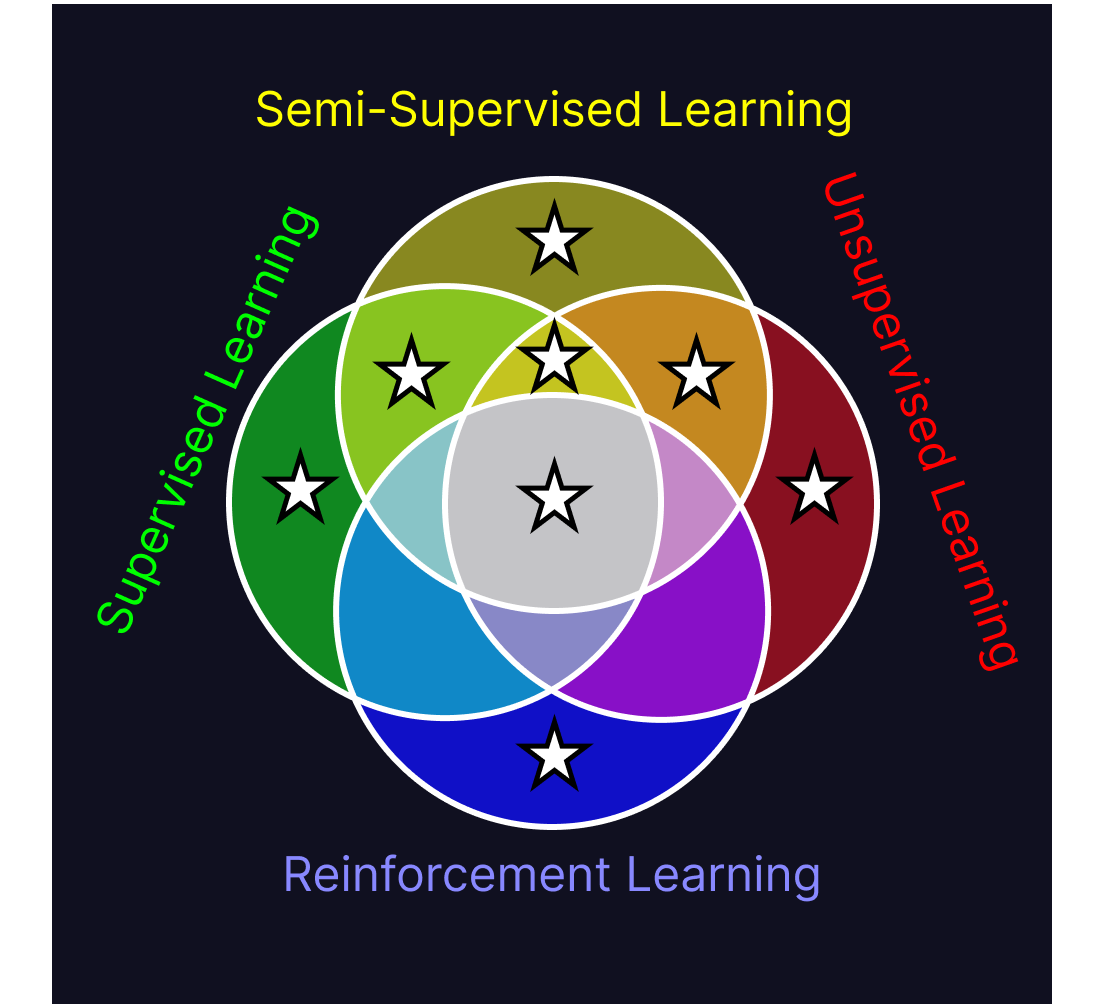
Reinforcement learning can be likened to supervised learning in that it uses prescribed feedback on its judgements to train its model, but it’s also similar to unsupervised learning in that it has to explore structure within the environment in order to figure out what sequence of events are required to trigger a reward. Though these different approaches to training are hard to reconcile into a single model, they have commonalities. All of these models use information from their training environment to perform a task better than they could prior to being exposed to that environment. Across all of the subfields of machine learning, a machine learning program is one which gains new abilities through exposure to its working environment.
Critiques of this Definition
Are Perpetual Learning Algorithms Machine Learning?
This definition is broad, and people could protest that it does not capture specific traits of the machine learning field. One thing that almost all machine learning algorithms have in common is a training period and a separate deployment period. This is the case because most algorithms are much more time consuming to train than to deploy, and so if the model can run in a deployment environment without simultaneously training it tends to be faster than if it remained training. This is why most machine learning models today are incapable of learning beyond their training stage—the resultant models have no learning capacity, but rather are the result of a learning period. Still, the average machine learning engineer wouldn’t say that perpetual learning algorithms fall outside of machine learning’s domain.
Is Caching Machine Learning?
Another contention could be that this definition covers algorithms which are not machine learning. Pure functions are programs which take input and produce a deterministic output. In other words, each specific input only has one output when used in that function, and that output never changes. Multiple outputs can have the same input, but each input always maps to the same output whenever the function is called with it.
For example, this pure function takes the square root of its input number, and every time I put in 100 it will always output 10.
1 2 3 | |
This impure function returns a random number between 0 and the input number. If I put in the number 15 three times, we’ll see three completely different results.
1 2 3 4 | |
Caching algorithms are wrapper algorithms which augment pure functions. What caching algorithms do is keep track of recently used input-output pairs to the function. When the function is called with a recently used input, the caching algorithm intercepts the call and returns the stored value, stopping the function from re-calculating it. For process intensive functions with few inputs, these caching algorithms can increase their speed drastically. In some sense, these caching algorithms fall under the definition of machine learning described above. In being exposed to their working environment (the function being called with test data), they improve the function’s operation speed. A caching algorithm which has never been exposed to any function calls will definitively not add any optimization to the first call it handles, but as it runs it becomes more effective until it reaches an upper limit on its ability to preempt what inputs will occur next.
Though some would describe caching as machine learning, most people I surveyed consider it too dissimilar from conventional machine learning. In interviewing colleagues about why they felt it was or wasn’t machine learning, all of the dissenters agreed on the reason they thought it wasn’t machine learning: caching does not provide enough new un-encoded functionality to qualify as machine learning. In this case, they actually agreed with my definition, and contended that caching algorithms do not acquire new skills, but rather use a pre-encoded method to accelerate pre-encoded functionality. In this sense, the definition we came to proves to be more robust, in that it aides people in clearly describing why a controversial model is or isn’t machine learning to them. A good descriptive definition gives people grounds to justify their gut instinct on whether something is or is not part of that definition.
How this Definition Helps Everyone
By striking a balance between descriptive and prescriptive definitions, it’s now clear what
machine learning is from the perspective of machine learning engineers. This doesn’t mean that
every reference to machine learning will fall under this definition; as mentioned at the start of
this article, the term will get misused by people who have a vague understanding of the term.
However, with the knowledge from this article, it’s easier to recognize when the term is being
used carelessly. As more people learn the technical meaning of machine learning the public
discourse surrounding it will become more precise and easier to understand for everyone involved.
It’s helpful when studying a subject to set the bounds on where that subject starts and ends.
Rigorous definitions help in defining what is on the table for discussion, which is especially
valuable when looking for novel approaches to difficult pr oblems. For the past ten years, the
most groundbreaking computer science advancements have been in machine learning. Those
achievements often1 (though not always2) were the result of novel perspective shifts on
algorithm design. Finding novel approaches within the bounds of machine learning means looking at
novel ways This concrete definition of what machine learning is helps computer scientists explore
the field’s unreached edges.